
I Was Learning Python When I First Heard About AI Agents
It all seemed so mysterious and incredible to me. It really sparked my curiosity and imagination. So I started to look into it with more detail. That's when I learned about crewAI.
crewAI is amazing and has many, many features, and I am sure that during my tests I was only scratching the surface. It was most likely overkill for my simple Python applications with some AI agents.
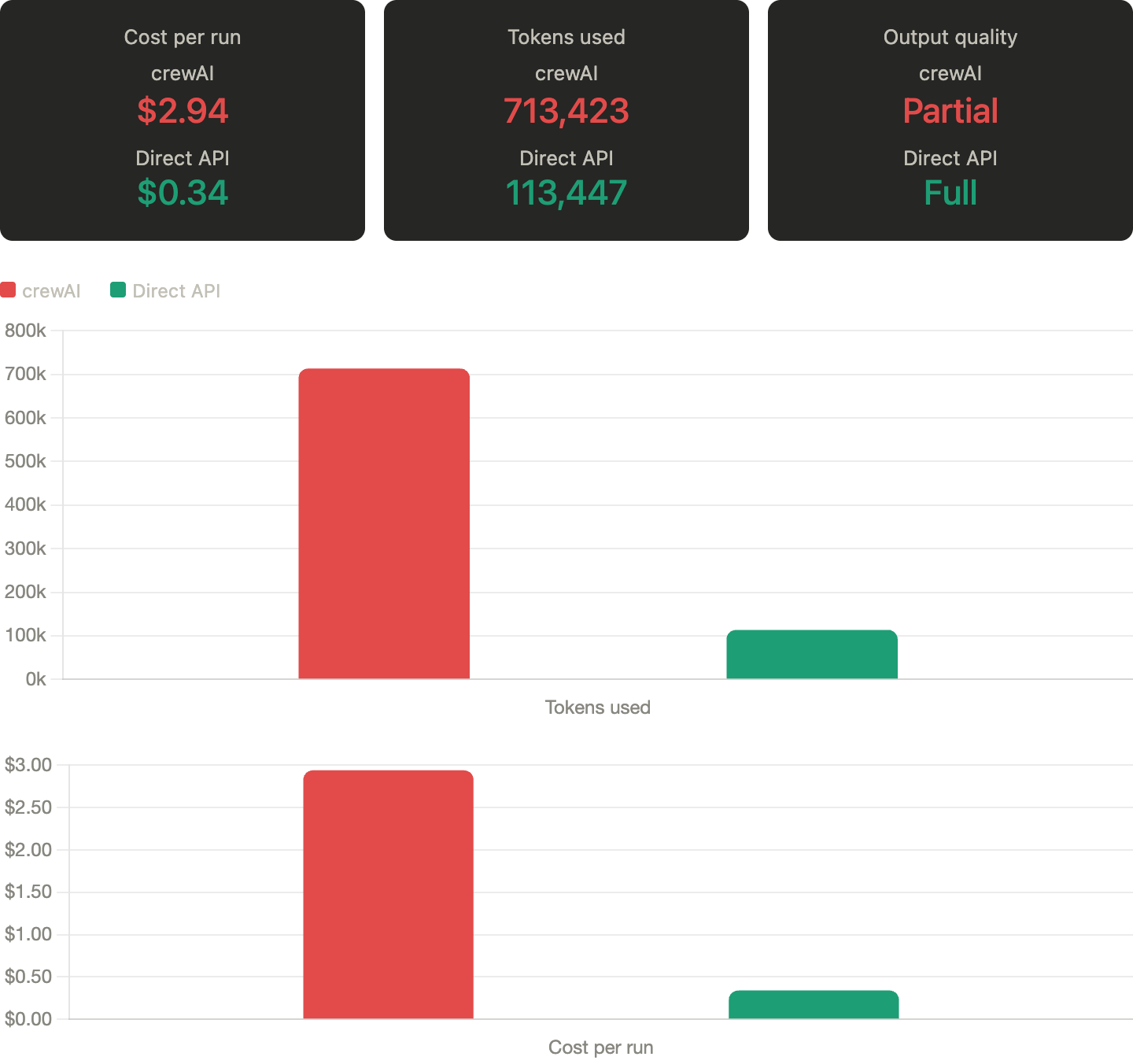
What I was building, and still am, is a digital marketing agency where agents allow me to generate detailed campaign briefs documentation and campaign specs. I tried via crewAI, and in my specific use case, each report run was costing me around three dollars. I most likely configured it wrong and wasn't able to fully optimize. The output quality was also not very solid.
I am sure the problem was not crewAI, but me not being able to extract the best from it. From what I understood, crewAI solves a different problem than the one I had. CrewAI excels at dynamic, multi-agent orchestration where roles, tools, and flows are not fully known upfront. It was overkill for my modest agent-based digital marketing agency.
And the cost issue is real, it's probably the number one complaint. Multi-agent systems mean multiple API calls per task. Each agent gets a new prompt plus context plus output. Agents also talk to each other, which means more tokens. Based on my tests, you're looking at roughly two to three times higher total cost versus simpler architectures.
I do confess that seeing agents interact and “learn” is pretty cool, but I dont have the budget for that.
$3.00 a Pop Meant I Could Barely Debugged Anything
With a three-dollar-a-pop scenario, my debugging was very limited to say the least. I am a perfectionist and given the opportunity, would have tested several times until happy with final results. Due to cost, this project did not progress much and output quality was low. The whole module was parked for a while.
Now with the new approach, using skill markdown files and Claude Sonnet APIs, my reports cost around $0.35 and consume on average 110K tokens. Unfortunately I don't have token count from the crewAI days for a direct comparison, but the cost difference alone tells the story: I went from barely being able to afford a debugging run to iterating freely.
The Breaking Point Was Seeing What I Was Actually Paying For
As I started to see other folks experiencing similar issues, Reddit posts were mentioning .md files directly with APIs, and libraries built around markdown files were becoming available and shared around.
My crewAI project was not progressing, and the breaking point came when I looked at cost and duplication side by side. I'd run the same workflow through crewAI and then manually inspect what each agent saw. Large chunks of context were being re-sent over and over: role definitions, prior outputs, instructions that didn't change. I realized I was paying for repeated scaffolding, not better reasoning. At that point, it became hard to justify the abstraction when I could see exactly what was being passed to the model.
So I stripped it down to first principles: what does an "agent" actually need to perform well? The answer was surprisingly minimal, a clear system prompt and the right context. That's it. The system prompt defines behavior, and the context with markdown files, defines expertise. Everything else, memory layers, orchestration logic, tool routing, only matters if the problem actually requires it. Mine didn't.
I love technology. I am always playing and testing new tools, new processes and I allowed myself to go crew.ai and scope creep my modest agency ;-)
The markdown approach came naturally from that. Instead of dynamically retrieving knowledge or embedding it in some vector system, I already had structured, high-quality domain knowledge. So why not just load it directly? Filename matching became the simplest possible routing mechanism. If the agent is "PPC Maestro," it gets the PPC files. No retrieval step, no scoring, no ambiguity, just deterministic context injection.
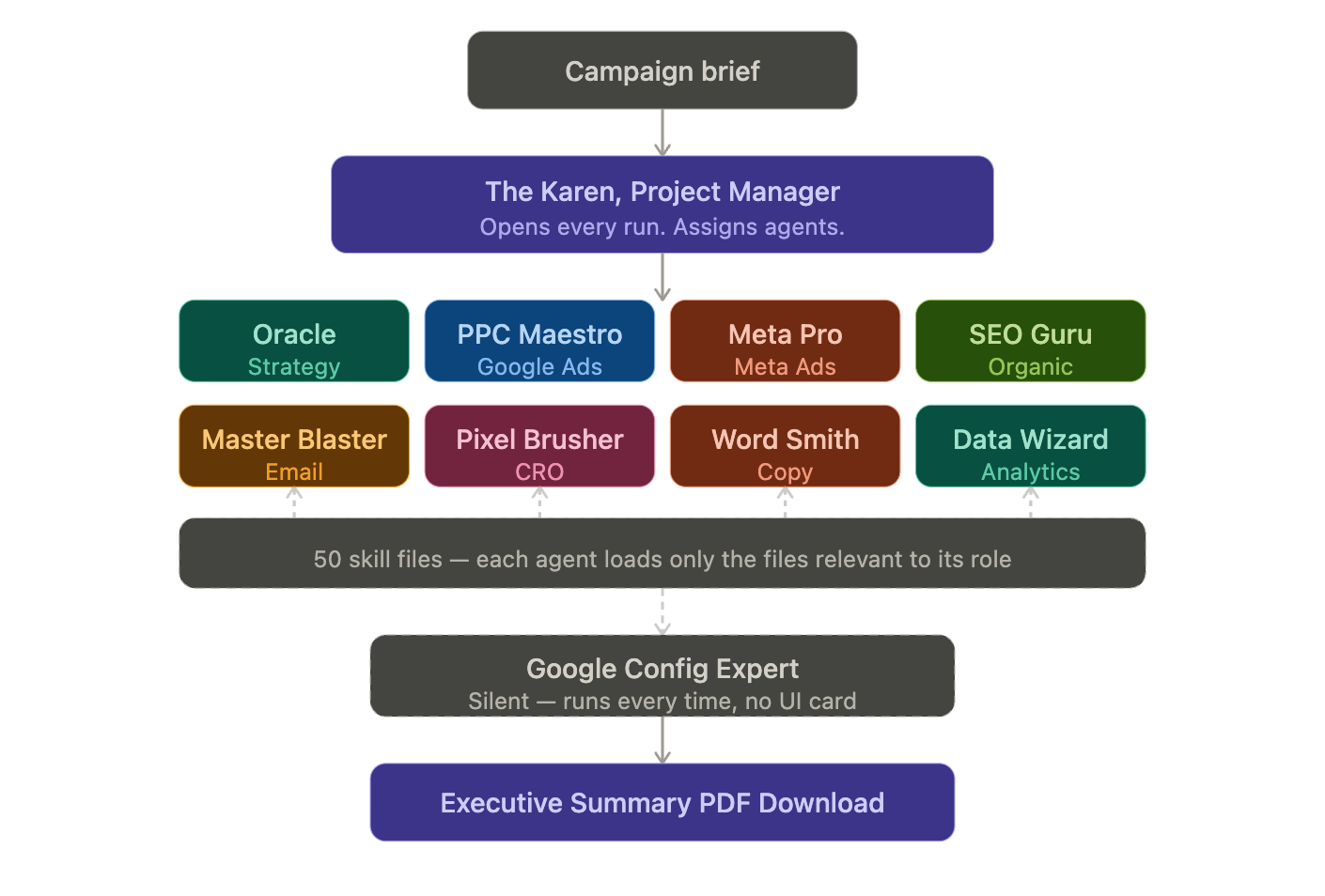
The Karen Runs First and Last: And That Double Pass Changed Everything
The setup has a PM agent named Karen (when she gets pissed, se releases the KraKaren) who bookends the entire workflow.
Karen first pass: Reads the brief, writes an opening that assigns each agent their role and sets the campaign tone. It's the context-setting pass. She frames what the campaign is trying to achieve before any specialist touches it.
Karen last pass: Reads everything all agents produced, then writes the executive summary. She synthesizes, flags conflicts between agents, and makes three critical decisions.
Those three decisions are defined in her system prompt and python instructions:
Budget arbitration: reconcile what specialists asked for against the actual budget. The outdoor gear run is the proof: she caught $16,500 in allocations against a $15,000 budget and resolved it line by line.
Conflict resolution: identify where two agents gave contradictory recommendations and pick a side or merge them. Landing page strategy was the example in the outdoor gear PDF: PPC wanted dedicated category pages, SEO wanted to keep existing product pages to preserve authority. Karen called it.
Priority sequencing: out of everything the team produced, what gets done in week one versus month two. She turned nine separate agent plans into one implementation timeline.
The Conflict That Proved the Double Pass Works
The one I can point to from the outdoor gear campaign PDF:
PPC Maestro said drive traffic to dedicated landing pages from day one. SEO Guru said keep traffic on existing product pages to protect ranking authority. Those are directly contradictory.
Karen's outro resolved it: existing pages in week one while SEO optimizes them, dedicated landing pages live in week three with redirects preserving authority.
Neither agent knew what the other recommended. Karen did.
The math is simple. At $3 a run you build cautiously. You cut corners on agents, skip iterations, and ship work you are not proud of because another test costs too much. At $0.35 you just run it again. That freedom is worth more than the $2.60 difference. The framework was not the problem. The ceiling it created was.
If your workflow is predictable, your agents have defined roles, and you know what context each one needs — you probably do not need an orchestration layer. A system prompt, a markdown file, and a direct API call will get you further than you think.